Benchmark: Supermetal vs Debezium vs Flink CDC
Independent benchmark shows 2x snapshot throughput with half the CPU and memory
This is a guest post reproduced with permission by Yaroslav Tkachenko, a software engineer & architect specializing in data-intensive applications, data streaming, stream processing, and distributed systems.
Supermetal recently launched Kafka sink support as a drop-in alternative to Debezium and Flink CDC.
CDC pipelines at scale face familiar tradeoffs: Debezium is battle-tested but operationally heavy. Flink CDC scales horizontally but adds coordination overhead. Both rely on JVM-based architectures with multi-hop serialization.
What happens when you rewrite the CDC layer in Rust with Apache Arrow? This independent benchmark answers that question with TPC-H SF=50 data (300M+ rows) replicated from Postgres to Kafka.
DISCLOSURE: This work was sponsored by Supermetal. All benchmarks were executed by the author in his own AWS account. All numbers and findings are shared as-is.
About CDC Tools
Supermetal
Supermetal is a CDC tool built in Rust and Apache Arrow. It ships as a single binary. Get the trial version here (includes 1000 hours of free sync).
It scales vertically by using all available CPU cores. It supports many popular databases and data warehouses. It runs without Kafka or an orchestrator: data flows directly from source to sink (with optional object storage buffering). See the architecture docs.
Supermetal supports both live (e.g. reading from a replication slot) and snapshotting modes. Snapshots are always parallelizable.
Configuration options include a built-in UI, REST API, or JSON config files. I used a JSON config file (a better fit for containerized workloads). The config file describes sources and sinks.
Debezium
Debezium is likely the most popular CDC tool in the world. It's implemented in Java and typically deployed as a connector in a Kafka Connect cluster. This means it relies on Kafka: CDC data is first ingested into a set of Kafka topics, and then can be delivered to sinks via another connector.
It supports most relational databases and some non-relational ones.
Debezium supports both live and snapshotting modes as well. Architectural detail: Debezium connectors (at least the most popular ones, such as MySQL and Postgres) can only be deployed as single-task connectors in the Kafka Connect cluster. Snapshotting can be parallelized by increasing the number of snapshot threads (a relatively new feature).
I deployed the Debezium connector with a simple, flat config file.
Flink CDC
Flink CDC started as a collection of Flink CDC sources; now it's a complete data integration framework. It's implemented in Java using Flink as the engine.
Flink CDC supports both live and snapshotting modes as well. For live mode, it mostly relies on Debezium, since Debezium can be deployed in embedded mode, which doesn't require a Kafka Connect cluster. For snapshotting, Flink CDC uses a custom implementation that relies on the Flink Source API. Most notably, this is the only of the three implementations that allows horizontal scaling of the snapshotting stage: input chunks (a range of a Postgres table, for example) can be processed in parallel across different TaskManager nodes.
Flink CDC supports YAML-based declarative pipelines, but since I used it as a source connector, I needed to implement a pipeline programmatically.
Test Setup
The goal: replicate data from Postgres to Kafka.
I used the TPC-H dataset with scale factor (SF) 50. TPC-H consists of 8 tables of varying sizes. At SF=50, the largest table (lineitem) has 300M rows, the second-largest (orders) has 75M rows, and so forth.
On the infra side, I had:
-
AWS RDS Aurora Postgres 16, 48 ACUs (increased to 96 later).
-
AWS MSK with 3 express.m7g.xlarge brokers.
-
AWS EKS 1.34 using m8i.xlarge nodes (4 CPU cores, 16 GB RAM).
- All workloads (Supermetal agent, Kafka Connect node, Flink TaskManager) ran on a single node each (configured to request 3.5 CPU cores and 13 GB RAM). Flink TaskManager used 4 task slots.
Regarding versions:
-
Latest Supermetal build (provided by the Supermetal team as a Docker image).
-
Flink CDC 3.5.0 with Flink 1.20 deployed using Flink Kubernetes Operator 1.13.
-
Debezium 3.4.1.Final with Kafka Connect 4.1.1 deployed using Strimzi Operator 0.50.0.
Generated Data
All three tools generated Kafka topics with JSON records. By default, Supermetal uses Debezium envelope schema. I confirmed the output is identical to what Debezium emits: not just payload fields, but message keys and headers too.
Flink CDC provides a standard JsonDebeziumDeserializationSchema for obtaining Debezium records as JSON, but requires implementing a Kafka serializer. The serializer I implemented produced the same Kafka message payloads, but I skipped the message keys and headers, which may have affected the rates below.
I spot-checked data across topics and observed no data loss.
Snapshotting Mode
Snapshotting is where I expected the largest performance differences. I also tested live mode, but skipped Flink CDC (since it wraps Debezium, performance would be similar or lower).
Supermetal
Baseline run with default configuration:
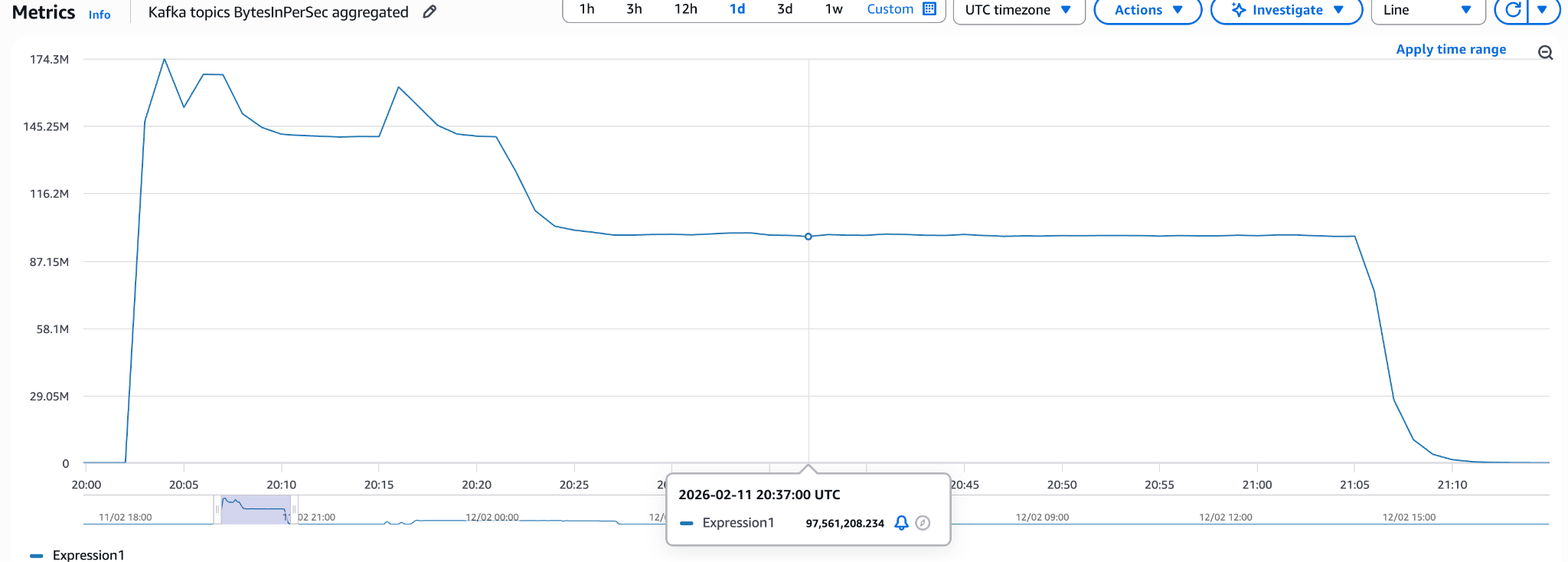
Finished in 72 minutes with 174 MB/s peak throughput and 105 MB/s average.
The Supermetal team recommended testing with:
-
Disabled intra-table chunking (parallel_snapshots_enabled = false). For Kafka sinks, this improves throughput since Kafka partitions are the bottleneck, not table parallelism. This is typically not needed for sinks like data warehouses.
-
Producer pool size equal to the number of input tables (8).
With these settings, the run finished in 60 minutes with 275 MB/s peak throughput and 123 MB/s average, the best result in this benchmark.
Flink CDC
Baseline run with default configuration:
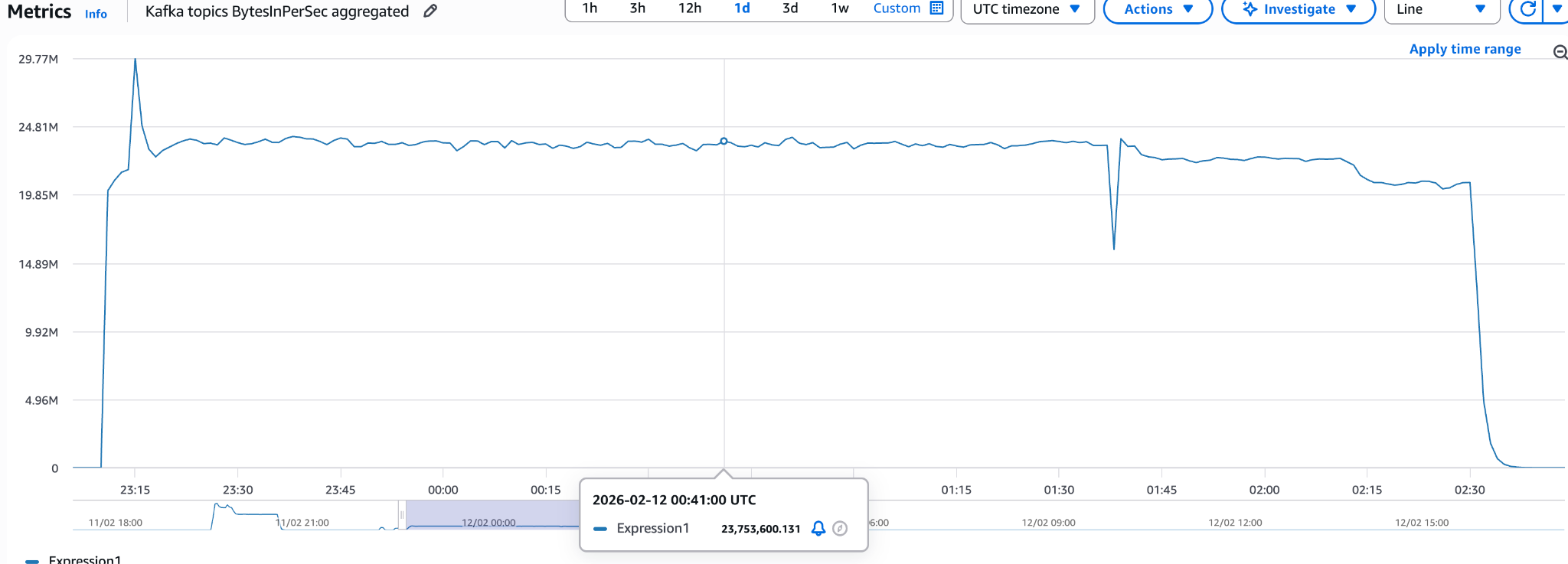
Finished in 210 minutes with 29 MB/s peak throughput and 22 MB/s average, significantly slower than Supermetal, but important as a baseline. Can we improve it?
First optimization: Kafka Producer tuning with linger.ms of 100 and batch.size of 1000000 (Supermetal's defaults). This change showed no performance gains.
Horizontal scaling: adding three more TaskManagers increased parallelism from 4 to 16. Throughput improved nearly linearly to 84 MB/s, but requires additional infrastructure.
Increasing fetch size to 5000 (from default 1024) and chunk/split size to 50000 (from default 8096) yielded 54 MB/s.
Debezium
Baseline run with default configuration:
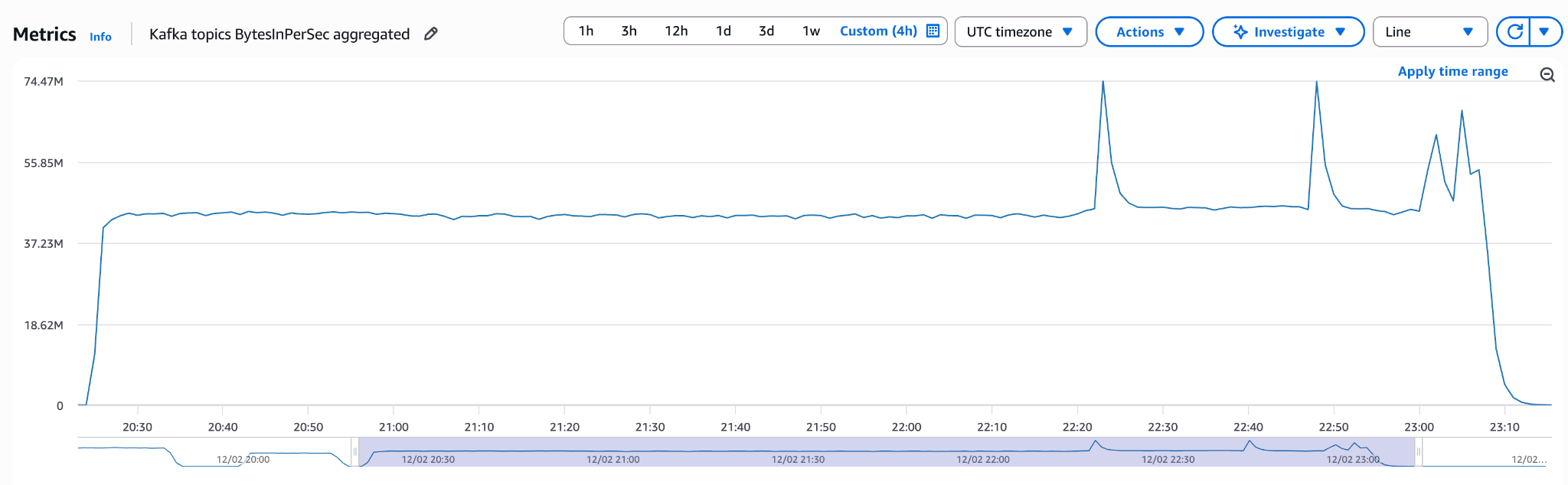
Finished in 170 minutes with 74 MB/s peak throughput and 43 MB/s average, slower than Supermetal, comparable to Flink CDC.
Kafka Producer tuning (linger.ms of 100, batch.size of 1000000) nearly doubled throughput to 100 MB/s.
Increasing snapshot threads from 1 to 4 reached 70 MB/s. Increasing to 8 threads showed no improvement.
Combining both optimizations performed worse than baseline, likely too much contention.
Live Mode
The data generator emitted TPC-H data at a consistent rate, writing to the two largest tables: lineitem and orders.
Debezium
With default config, Debezium sustained 15k ops/s. At 30k ops/s, replication lag started growing.
With tuned batch.size and linger.ms, Debezium sustained 30k ops/s. Replication slot lag remained around 800 MB.
My data generator maxed out at ~35k ops/s, even after increasing Postgres to 96 ACUs. A different Postgres setup could push higher.
Further Debezium throughput improvements are possible via max.batch.size and max.queue.size. Reducing Kafka Connect flush time could lower replication slot lag.
Supermetal
Supermetal sustained 35k ops/s with default config. Replication slot lag stayed below 100 MB.
For live data, latency matters as much as throughput. Latency was not the focus of this benchmark, but the replication lag results are promising.
Other Notes
Supermetal used the CPU more efficiently (typically ~50% of the allocated 4 cores), while Debezium and Flink CDC mostly stayed around 25%.
Supermetal also used less memory (2GB), whereas Debezium and Flink CDC consumed much more (8GB - 10GB).
Analysis & Conclusion
Parallelization
Comparing the graphs: Debezium and Flink CDC both achieved a throughput level and held it steady throughout the test. Optimizations affected the rate but not the shape.
Supermetal behaved differently: a large spike at the beginning as it processes tables in parallel, then throughput decreases as only the largest table (lineitem) remains.
This suggests Supermetal parallelizes more efficiently and could achieve even better throughput with larger tables.
Transformations
Supermetal uses Apache Arrow's columnar format, which should deliver better performance when transformations (filters, projections) are involved, thanks to vectorized compute kernels.
Supermetal does not support transformations yet, but it's on the roadmap. A follow-up benchmark could test whether columnar data layout widens the performance gap.
Summary
Supermetal delivers the best performance. Debezium and Flink CDC, once optimized, can get close. Supermetal also shows better resource utilization (half the CPU, quarter the memory) and simpler operations (single binary, no orchestrator).
If you think Rewrite Bigdata in Rust is hype, reconsider. Expect more tools designed to run efficiently on modern hardware.
If you need to optimize Debezium or Flink CDC pipelines, tune the Kafka Producer configuration and consider the best way to parallelize snapshots.
Flink CDC has a working horizontally scalable snapshotting mechanism. With enough compute, it can match or exceed Supermetal's throughput.
Horizontal scalability may seem essential, but eventually the database becomes the bottleneck. Logical sharding by table (8 Supermetal agents or 8 Debezium tasks, one per table) can push throughput further, though it adds operational complexity.